
如何使用共享session来加速 Playwright 运行速度
· 1,880 词 · 10 分钟 读完 playwright进阶 翻译
测试执行越快越好 — 我们可以更快地检查更改的结果。然而,一如既往,这取决于我们正在测试的应用程序的复杂性。
用例描述 — 简介
假设我们有一个应用程序,它至少允许三种类型的用户:只读、读写和管理员。每种类型都有一些可以执行的专用操作,但 UI 通常是相同的。还有一个登录表单用于验证特定上下文。我们也可以假设我们至少有六个 describe — 在 Playwright (以及 Protractor) 中意味着测试组(或测试套件)。每个 describe 都在单个 spec 文件中 — 如下例所示。
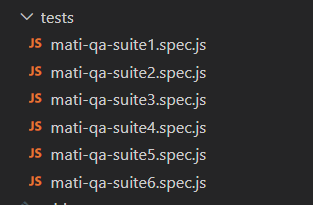
每个 describe 至少包含 3 个测试用例,这些测试完全独立于彼此。项目配置为使用 'fullyParallel' 标志,该标志已启用。顺便说一下,每个 describe 都包含一个 'beforeAll' 钩子,其中执行登录过程。describe 内的测试使用相同的上下文,即相同的用户。因此,如果我们以 串行模式 运行,那么每个 describe 将只执行一次登录过程,然后测试将一个接一个地执行。但我们使用的是 fullyParallel 模式,这意味着每个实例都将为自己执行登录过程。
第一个问题:如果我们只有 3 个用户上下文(只读、读写、管理员),为什么不只使用 3 个 'describe'?我的观点是,如果我们使用 fullyParallel 模式,每个启动的浏览器实例都将为自己执行登录过程。我还有一种感觉,我们将套件分得越多,就越能更好地管理它们,并行性也越好。在我的实验中,有时同一个 describe 内的用例的并行执行会被阻塞 — 不知道为什么 — 也许是某些 playwright 功能。;)
言归正传:我们如何加速这个过程?这里我将重点关注登录过程。在 playwright 中,我们可以轻松处理浏览器的 session 存储,正如你所知,所有负责用户授权(或保持用户身份验证)的 cookie、令牌和其他内容都存储在那里。因此,有一个名为 storageState 的方法 — 允许你将所有浏览器存储导出到文件中。但如何使用它呢?让我们看看需要做哪些更改。
示例用法
当前状态:
示例 mati-qa-suite2.spec.js 内容:
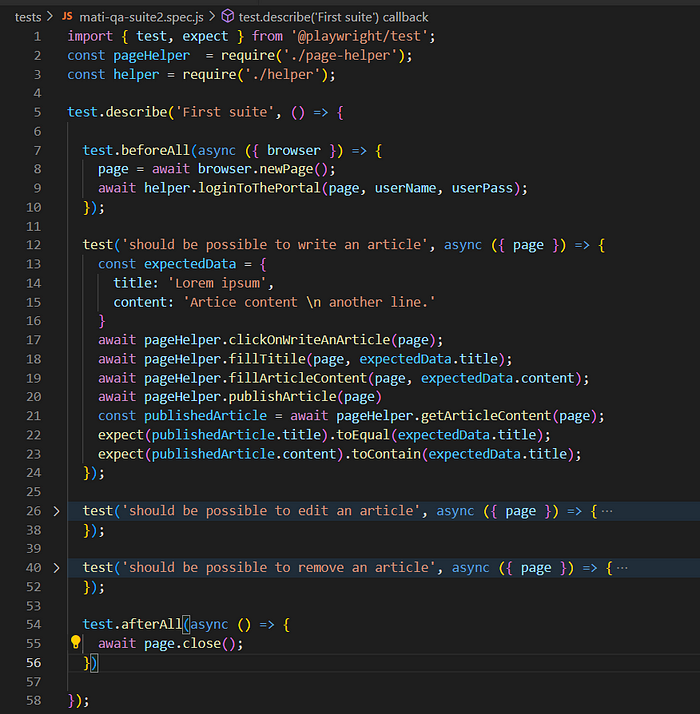
默认的 playwright.config.js:
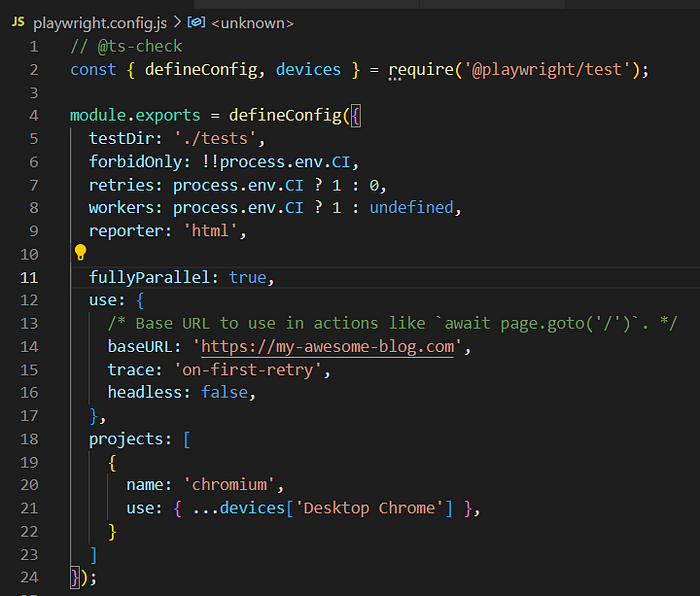
如你所见,登录过程是从辅助文件中导入的(因为我们试图保持 PageObjectPattern) — 所以,所有登录所需的代码都存储在那里。这里是该方法可能的样子:
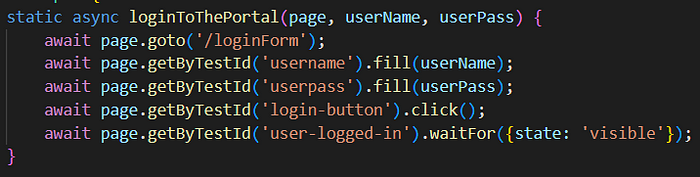
最后一行(使用 'waitFor' 方法)是为了确保我们已登录并可以继续。所有的 spec.js 文件都类似,只是用户上下文不同(只读、读写、管理员)。因此,再次强调,由于 fullyParallel 模式,每个浏览器实例都将使用自己的身份验证 — 这可能需要长达 10 秒的时间。在最坏的情况下,它将尝试为每个测试单独进行用户身份验证 — 大约 18 次 — 180 秒 — 3 分钟。
更改
为了加速这些过程,需要进行以下更改:
将我们的登录过程调用提取到一个单独的 spec 文件中,比如 read-only.session-creator.spec.js。基本上,你只需创建一个新的 spec.js 文件,并从那里调用 loginToThePortal 方法。唯一的变化是添加一行代码,在成功登录后导出存储状态。以下是它可能的样子:
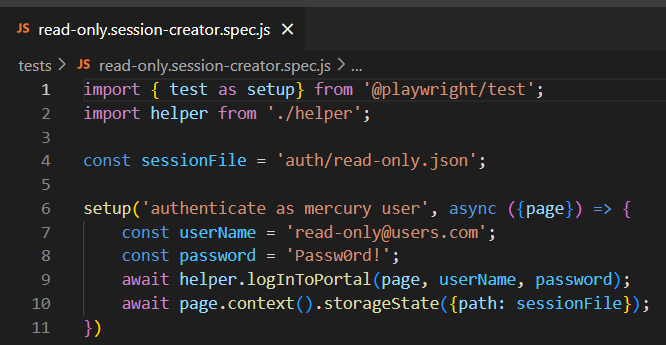
如你所见,这几乎是一个常规的 spec.js 文件。唯一的区别是我们从 Playwright 导入 test 并将其别名为 setup(代码的第一行)。然后我们定义一个 const 变量,包含我们将存储收集的浏览器 session 的文件路径。无论文件是否存在 — 如果不存在,将创建文件;如果存在,将覆盖文件。然后有一个 'setup == test' 块,其中我们调用我们的登录方法,最后(第 10 行)我们使用 storageState 方法和参数路径(定义的变量)保存/保存浏览器 session 存储以供进一步使用。
在 playwright.config.js 中更改项目。我们需要为每个用户上下文添加一个额外的项目。这些项目只负责运行那些 session-creator.spec.js 文件。然后,我们需要为相关的测试套件添加依赖项。以下是其中一对可能的样子(由于我们有三个用户上下文,我们需要三对):
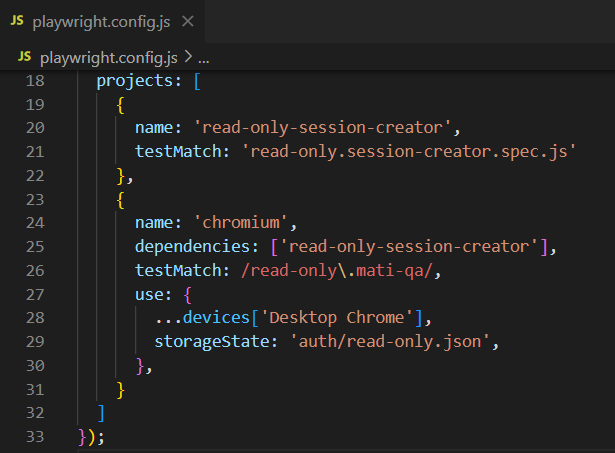
如你所见,我们有一个具有特定名称的新项目和 testMatch 属性,它可以是正则表达式或应执行的套件的直接名称。在我们的示例中,这是我们的 read-only.session-creator.spec.js 文件。然后我们需要根据名称为我们的主项目添加依赖项(上面屏幕的第 25 行,等于第 20 行),并在 use 标签内,我们需要设置将使用的 storageState(第 28 行)。我们还应该更新/重新考虑我们的 spec 文件名。我在这里建议为每个 spec 文件添加用户上下文名称作为前缀。因此,我们将使用 read-only.mati-qa-suite1.spec.js 而不是 mati-qa-suite1.spec.js。我认为,这是根据用户上下文区分套件的最简单方法。我们也可以在 describe 中使用标签,但这样查找使用特定上下文的 spec 会有点痛苦,因为我们需要打开每个文件并查看 describe 标题。
在我们执行登录的地方进行小改动 — 我们只需要调用输入 URL,而不是登录过程。因此,在我们包含所有用例的主 describe 中,我们需要做以下更改:
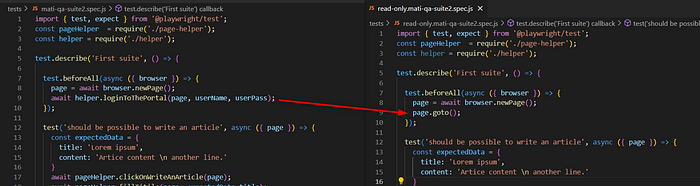
就是这样。现在,无论运行多少个浏览器实例,每个用户流程登录只会运行一次 — 所以,总共 3 次。经过所有更改后,我们的 'spec 结构' 应该是这样的:
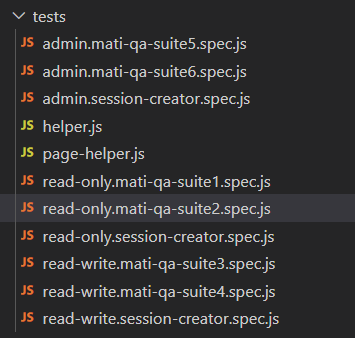
当然,我们现在可以稍微组织一下(在文件夹之间拆分,例如,admin、read-write、read-only),但这只是一个例子,所以不必漂亮。;)
结论
如你所见,有时即使是这样一个简单的更改也可能加速你的测试执行速度。当然,一切都取决于具体情况,但在大多数情况下,如果你的 / 你正在测试的应用程序包含登录流程,使用这种方法(共享 session)总是比显式登录更好。你永远不知道,当你的测试数量超过 100 时,每一秒都很重要。所以,玩得开心,多试验。;)
来源
发布时间: 2023-09-25